Les stratégies métacognitives de la compréhension et analyse automatique par ReaderBench, un système d’analyse automatique des stratégies
Contributeurs : Maryse Bianco, Philippe Dessus & Aurélie Nardy
Auto-explication et développement des stratégies de lecture (Aurélie Nardy, Maryse Bianco, Martine Rémond & Françoise Toffa, Laurent Lima)
Le protocole consiste à demander aux participants de lire un texte de manière segmentée et d’exprimer à haute voix ce qu’il a compris à chaque point d’interruption, figuré par l’image dans le tableau ci-dessous.

Les stratégies de lecture observées par l’intermédiaire de protocoles d’auto-explications peuvent donc être définies comme « les opérations mentales impliquées au cours de la lecture, lorsque le lecteur cherche à extraire le sens des mots qu’il lit » (Millis & Magliano, 2012). Elles témoignent des opérations mentales et des comportements de régulation sollicités pour construire une représentation cohérente de ce qui est lu.
Stratégies de lecture extraites des auto-explications des enfants
Stratégies
Exemples : Auto-explications correctes (caractères normaux), erronées (caractères italiques)
Paraphrases
Reprises mot à mot ou reformulations du texte
[P1, CM1] Ben c’est euh Matilda et sa famille y mangeaient comme tous les soirs devant la télévision
[P1, CM1] ben y…y le monsieur ‘fin ou la dame et ben y redisent : « Salut, salut, salut »
Inférences textuelles
Mise en lien d’informations non reliées explicitement dans le texte
[P2, CE2] c’est sa femme qui lui dit : « tu te décides » // et... Il avait pas très envie d'y aller
[P2, CE2] et en fait c’était pas des voleurs c’était un jeu de héros un jeu
Inférences de connaissances
Mise en lien d’informations du texte avec ses connaissances sur le monde
[P2, CM2] c'est une famille peut-être assez riche parce qu'il y a de l'argenterie
[P1, CE2] Y a quelqu'un qui qui entre et qui qui dit salut salut salut
Auto-évaluation
Tout ce qui exprime explicitement le fait d’avoir compris ou non, de se poser une question
[P1, CM2] Ensuite, ils arrêtent tous de manger, et je sais plus comment elle s’appelle, elle éteint la télé
[P2, CE2] et la mère elle pensa que i zétaient en train de voler......l’ar-gen-tine, et c'est quoi l'Argentine ?
Évolution des types de stratégies utilisées dans les auto-explications en fonction du niveau scolaire (en fréquence moyenne) (d’après Bianco, Dessus, Nardy et al., 2013) .
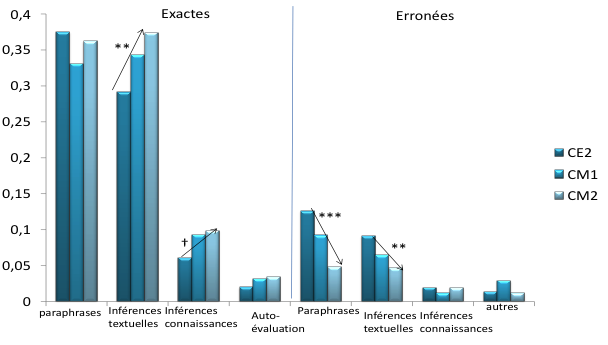
Tout le répertoire des stratégies décrites chez les adultes est présent dans les verbalisations enfantines dès l’âge de 8 ans :
- Deux stratégies dominent à tous les âges : la paraphrase et les inférences textuelles :
- les élèves de CM2 font significativement plus d’inférences textuelles (F(2,73) = 6,49, p = .002) alors que les paraphrases dominent au CE2.
2 les paraphrases erronées diminuent substantiellement au cours du cycle 3 F(2,73) = 8.12, p =.0007), de même que les inférences textuelles erronées (F(2,73) = 5.36, p = .007).
À chaque niveau scolaire, les faibles compreneurs ont tendance à faire plus de paraphrases (F(1,73) = 3.52, p=.06) et plus d’inférences textuelles (F(1,73) = 3.99, p=.05) inexactes.
Ces résultats ont l'objet d'une communication au congrès de la Society for the Scientific Study of Reading (2013).
ReaderBench, un outil d'analyse automatique des verbalisations de compréhension
Contributeurs : Maryse Bianco, Philippe Dessus, Aurélie Nardy, ainsi que Mihai Dascalu, Bogdan Oprescu et Stefan Trausan-Matu membres de k-teams, Université "Polytehnica", Bucarest, Roumanie.
Une première version de ReaderBench (Dascalu, Dessus, Trausan-Matu, Bianco, & Nardy, 2013) a été conçue et implémentée. Elle permet la détection automatique des paraphrases, du contrôle, de la causalité (ces deux dernières stratégies, en détectant des patterns de mots), des inférences de concepts et de brigding.
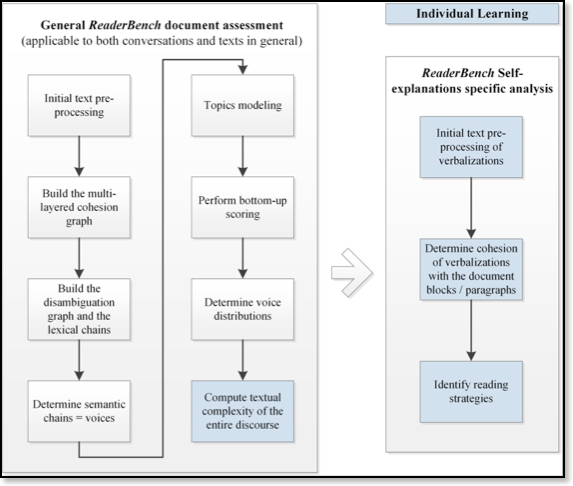
Voici, tout d’abord, une brève présentation du fonctionnement et de l’interface de ReaderBench. ReaderBench est un système, écrit en Java qui intègre de nombreuses bibliothèques d’analyse automatique de la langue. Il permet de réaliser diverses mesures sur les textes à finalité d’apprentissage qu’on peut lui soumettre. La Figure 1 présente une vue d’ensemble des différents processus à l’œuvre dans ReaderBench, du point de vue de l’apprentissage individuel (les aspects de l’analyse de l’apprentissage collaboratif ne sont pas mentionnés). La boîte de gauche résume les processus communs. Se reporter à Dascalu (2014) pour plus de détails dans l’implémentation.
Figure 1 — Les différents processus à l’œuvre dans ReaderBench (Dascalu, 2014).
Nous ne centrerons ici que sur la description de l’analyse des stratégies de compréhension en lecture. Tout d’abord, l’utilisateur peut utiliser une interface de saisie suivante permettant à tout enseignant de saisir un nouveau texte à lire, après avoir mentionné quelques métadonnées (auteur, niveau, etc.). Une fonctionnalité permet d’insérer des points de verbalisation. Ensuite, un fichier XML est généré à partir de ces informations (il est aussi assez facile d’écrire ce fichier directement, sans passer par l’interface), et ce texte peut ensuite être traité par ReaderBench. Il est nécessaire de spécifier la langue du document, et l’espace dans lequel il va être traité (LSA/LDA).
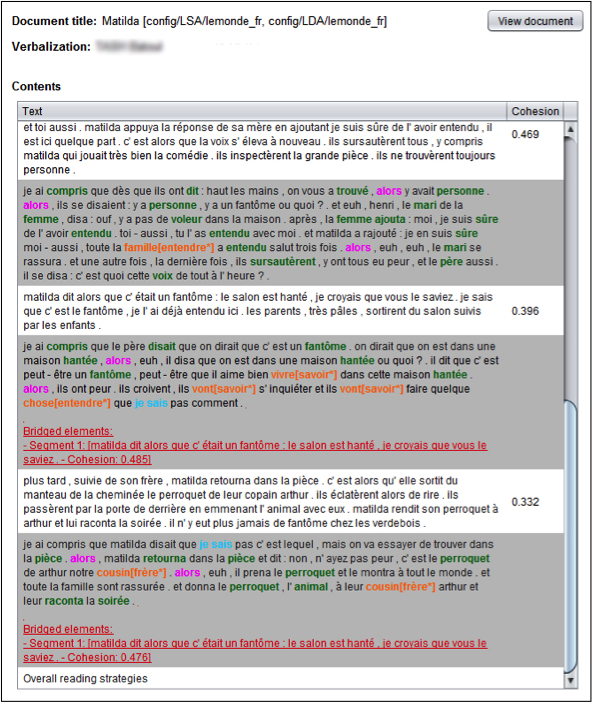
Ensuite, le lancement du traitement de la verbalisation (ce traitement peut se faire aussi par lots) affiche la fenêtre suivante (Figure 2), qui contient à la fois le texte lu (paragraphes sur fond blanc) et les verbalisations d’un élève donné (sur fond gris). La colonne de droite mentionne la cohésion entre 2 paragraphes du texte. Chaque couleur représente une stratégie (contrôle, causalité, paraphrase), l’astérisque représente une connaissance inférée (avec le mot inféré entre crochets). Les éléments sujets à un bridging sont listés en souligné à la fin de chaque verbalisation.
Figure 2 — L'analyse des verbalisations dans ReaderBench.
Décrivons maintenant les différentes études de validation de ReaderBench. Une première étude sur 72 verbalisations donne des résultats encourageants en termes de précision et rappel. Une deuxième version (voir Tableau X) a été implémentée et testée sur un nombre plus grand de verbalisations.
Les principaux résultats de ce tableau montrent que les stratégies de causalité et de contrôle sont les plus aisées à reconnaître. Les paraphrases sont également identifiées de manière satisfaisante. Des progrès ont été réalisés, entre les deux versions, concernant les inférences de connaissances et le bridging. Ces stratégies restent néanmoins plus difficiles à identifier. La deuxième version du système a été utilisée (Dascalu et al., 2014) pour tester si ReaderBench pouvait être utilisé pour prédire le niveau de compréhension des élèves. Trois catégories d’élèves ont été créées arbitrairement (30 %, 40 % et 30 % des scores, classés par niveau croissant) et un algorithme de classification nommé « Séparateur à vaste marge » (Support Vector Machines, SVM). Cet algorithme permet de classer des données multidimensionnelles et a donné de bons résultats dans le domaine de la classification de textes (François & Miltsakaki, 2012). Tout d’abord, nous avons entraîné le classificateur SVM sur les 2/3 de l’ensemble textes-verbalisations-scores de compréhension, ce qui permet de réaliser les classes les plus pertinentes. Ensuite, le restant des textes été utilisés (sans les scores de compréhension) et le SVM a prédit leur niveau de compréhension en fonction des stratégies utilisées à 78 %.
Une réflexion pédagogique sur les usages de ReaderBench a également été menée (Dascalu, 2014 ; Dessus et al., 2013), montrant que les différentes fonctionnalités de cet outil peuvent prendre place dans un flux d’activités impliquant l’enseignant et l’apprenant. L’enseignant peut tout d’abord utiliser les fonctionnalités d’analyse de la complexité textuelle pour choisir l’ensemble de textes les plus appropriés au niveau de ses élèves. L’apprenant prend ensuite connaissance des textes et peut opérer sur ces derniers un ensemble de mesures : graphe de cohésion, liste de thèmes, phrases les plus importantes, interanimation de voix dans le document. L’apprenant peut à tout moment, soit résumer, soit expliquer ce qu’il a compris du texte, soit enfin trouver les mots-clés et/ou les phrases importantes (sélection qu’il pourra comparer avec celle fournie par ReaderBench). Ensuite, le système lui fournit une analyse des stratégies utilisées dans son explication ou son résumé. L’enseignant pourra, enfin, prendre connaissance de ces différentes données et choisir un nouvel ensemble de textes.